
Notes:
Some factoids about the Chinese, Japanese, and Korean languages and their digital textual representations
Hopefully interesting but also useful to the practicing programmer
(I’m not a fluent speaker or reader in any of these languages.
TODOget reviewers.)
Why lump these three extremely different languages into one abbreviation? Seems problematic?
👋 Handwavium 👋 CJKV Information Processing by Ken Lunde, a 900-page door stopper
Notes:
Chinese, Japanese, and Korean (and here Vietnamese) get lumped together because, to varying degrees, they all make use of Chinese characters, which have traditionally been very interesting from a digital representation perspective
This is compounded by the fact that all these also use other scripts with their own quirks, so there are many considerations for correct and readable textual representation
There is no doubt also a sociopolitical dimension—these languages represent wealthy, powerful countries with considerable interest in seeing their text digitized. Engineers like Lunde who worked to support one of these languages on early computing systems likely also worked with the one or more of the rest.
Another interesting commonality: their scripts (Chinese characters and others) are readily monospaced.
Let’s start with some technical foundations.
Character set and character encoding
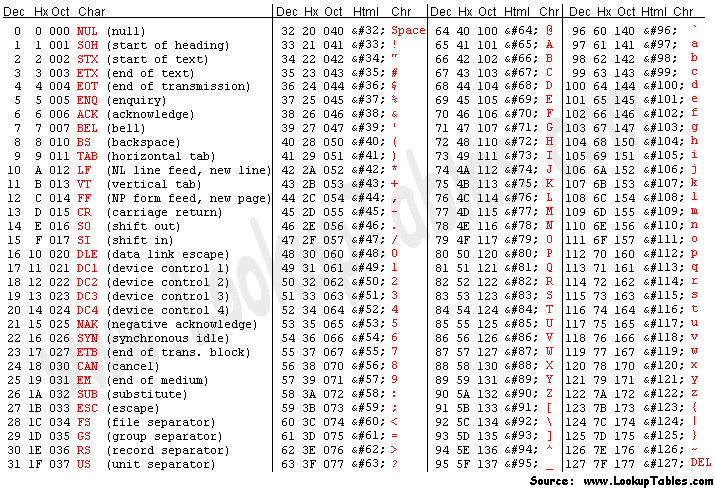
Notes:
ASCII is a mapping from the first 128 seven-bit numbers (0 to 127: 2**7 = 27 = 128) to characters. Most of these characters are printable, but some are invisible.
Like The Martian, we should all have a copy of this table somewhere handy (I’ve referred to http://www.asciitable.com since school).
Given that most CPUs you and I might program today have a byte (eight bits) as the smallest addressable data width, ASCII fits snugly in one byte.
Unicode: character set, UTF-8: character encoding
| Byte 1 | Byte 2 | Byte 3 | Byte 4 | Unicode range |
|---|---|---|---|---|
| 0xxx xxxx | U+0 to U+7F (ASCII!) | |||
| 110x xxxx | 10xx xxxx | U+80 to U+7FF | ||
| 1110 xxxx | 10xx xxxx | 10xx xxxx | U+800 to U+FFFF | |
| 1111 0xxx | 10xx xxxx | 10xx xxxx | 10xx xxxx | U+10000 to U+10FFFF |
Notes:
Many (but not anywhere near all!) documents you’ll encounter today will be UTF-8 encoded. This means that the bytes in memory follow the above pattern and can be rapidly grouped into characters of one to four bytes (eight to thirty-two bits):
This is a really carefully-designed code that satisfies many competing requirements: compactness, self-synchronizing, error handling, and more!
The binary values in the x spaces above contain the character data: these specify which Unicode point this sequence of bytes represents.
We’ll come back to Unicode, but let’s talk about these languages.
Notes:
To linguists like @lynnguist (above) and John McWhorter, languages are spoken
Their written representations are a very ancillary concern
The main linguistic concept we’ll invoke is that, while two languages that live next to each other may mix a lot of vocabulary, their bones tend to stay fixed. Differences in syntax and grammar—how the languages put words and sentences together, what they choose to emphasize—tend to persist.

Notes:
Image: excerpt from Wang Xizhi (303–361 CE), “Sunny after Snow” calligraphy model on paper, most likley a Tang (618~907 CE) copy
It’s well-known that “Chinese”, as any kind of unified spoken language, is a politically-backed mirage: Mandarin, Shanghaiese, Cantonese, Fujianese, etc., are mutually unintelligible and vary considerably “in grammar, syntax, phonology, vocabulary, etc.” (Language Log)
(This mirage may harden into reality as the winner-take-all dynamics of lingua francas, helped along by the People’s Republic of China’s active efforts, slowly kills some of these non-Mandarin languages)
However! Speakers of these languages will use Chinese characters to write, so please let me keep the title of this section “Chinese writing”
For a delicious deep dive into how, for example, Cantonese speakers write/tweet Cantonese, see Zev Handel's epic thread (unrolled).

Notes:
Image: bone fragment, 1300-1050 BCE. Sackler Gallery, Smithsonian
Like every writing system invented (until the Phonecians invented an abjad, which led to alphabets and syllabaries), the ancient Chinese used pictograms. They carved these representations on bone or turtle shells.
The earliest of these representations come from oracle bones found dating from the Shang dynasty. They were inscribed on ox bones or turtle plastrons (undershell), which were then heated till they cracked, or stabbed with a hot poker—the cracks were inspected for divination. Thousands of characters have been found on these bones and shells, indicating a long incubation period that is alas as of now invisible in the archaeological record.

Notes:
Image: turtle carapace, 1300-1050 BCE. Sackler Gallery, Smithsonian
Imagine the sun 🌞
| 1500 BCE (bone) |  |
| 800 BCE (bronze) |  |
| 300 BCE (bamboo) |  |
| 200 BCE |  |
| Today | 日 |
Notes:
Images from Wiktionary




Today:
目
(A box with two lines, or 👁 👀)
Notes:
Images from Wiktionary
New characters for words whose representation hadn’t been decided could be invented in any number of ways.
👩🎨🖌
昌: two suns: sunlight, prosperous, beautiful, …
林: two trees (木): woods
森: three trees: (guess!)
姦: three women (女): today solely negative dictionary definitions (really, ancient misogynistic men writers, really? 🤦)
Combine meanings
・・・・
Combine sound:
Notes:
Writing with a brush (which even the Shang people did, on bamboo, etc.) can lend itself to creativity in constructing new pictographs.
Although today spoken Mandarin only has around 450 syllables (many of which exist in multiple tones), Old Chinese had considerably less homophony. But this was another source for innovation in characters.

Notes:
Image: self: poster of all 2136 Japanese grade school kanji from KanjiPoster.com
This leads to the classic data representation problem: literally thousands of characters for daily use—
We’ll get to it soon but to acknowledge the elephant in the room: Unicode has made things much better but it made things much worse at first, and it had to come from somewhere!
GB2312, introduced in 1980, was a list of 6,763 Chinese characters plus alphabets/syllabaries for Greek, Russian, and Japanese.
It uses one or two bytes for each character. Like UTF-8, it is ASCII-compatible: if a byte is between 0x00 and 0x80, then it must be ASCII. If a byte was greater than 0x80, it was a part of a 2-byte character; unlike UTF-8, you don’t know whether it was the first byte or the second byte.
In practice, GB 2312 used 0xA0 to 0xFF: (255 - 160)**2 = 9025. With some private use area (PUA), you get the ≈7000 characters.
Derived from the Chinese telegraph code, whose “codebook … shows one-to-one correspondence between Chinese characters and four-digit numbers from 0000 to 9999. Chinese characters are arranged and numbered in dictionary order according to their radicals and strokes [counts]. Each page of the book shows 100 pairs of a Chinese character and a number in a 10×10 table. The most significant two digits of a code matches the page number, the next digit matches the row number, and the least significant digit matches the column number.” (Wikipedia)
Notes:
Video: Toshiba typewriter, produced 1940–1954. 1172 total characters (YouTube; Virtual Typewriter Museum)
Bopomofo is an alphabet for Mandarin and related dialects (as in, real dialects), encoding consonants and vowels and tones, developed in the early 1910s during the Republic of China years. Popular in Taiwan.

Note:
Image: Taiwanese cell phone Source
| bㄅ | pㄆ | mㄇ | fㄈ | |
| dㄉ | tㄊ | nㄋ | lㄌ | |
| gㄍ | kㄎ | hㄏ | ||
| jㄐ | qㄑ | tㄒ | ||
| zhㄓ | chㄔ | shㄕ | rㄖ | |
| zㄗ | cㄘ | sㄙ | ||
| aㄚ | oㄛ | eㄜ | ehㄝ | |
| aiㄞ | eiㄟ | auㄠ | ouㄡ | |
| anㄢ | enㄣ | angㄤ | engㄥ | erㄦ |
| iㄧ | uㄨ | iuㄩ |
Symbols are chunks of “normal” Chinese characters:
b ➜ ㄅ, from 勹, which in 包 is pronounced “bāo” (🥟)
p ➜ ㄆ, from 攵, which in 攴 is pronounced “pū” (“to tap”)
m ➜ ㄇ, which is 冖, pronounced “mì”, the cover radical
f ➜ ㄈ, which is 匚, pronounced “fāng”, the right open box radical
Pinyin is also an alphabet for Mandarin, encoding consonants and vowels and tones, but developed in the 1950s by the People’s Republic of China, and so had to use entirely different characters: Latin letters.
Easy for English speakers to learn!
| Q | “ch” (like Qin dynasty) |
| C | “ts” (like Tsai Ing-Wen) |
| X | “sh 😊” (like Xinjiang) |
| Sh | “sh ☹️” (like Shanghai) |
| Zh | “j 😊” (like Guangzhou) |
| J | “j ☹️” (like Xi Jinping) |
Notes:
Video: Fluent in Mandarin
Due to the high amount of homophony in Mandarin, IME tends to be slower than using non-phonetic input. You type in a string of sounds and usually your smartphone gets the characters right (sentence context, usage history, global patterns), but if not you have to select which character you meant.
This has been a major problem with React and other browser frameworks that want to own text input fields.

Notes:
Image: from Lunde, CJKV Information Processing, figure 2-2, showing the breakdown of 作 (つく.る) into radicals (亻 + 乍) and strokes
If you’re familiar with writing a character (something increasingly rare after leaving school), you can specify its component pieces for rapid lookup of a character.

Notes:
Image: a Wubi keyboard. Source
There’s only so many of these components, and each key on a QWERTY keyboard maps to a certain set of character components (often themselves characters).
You type the components in the same order that you write them (stroke order being fixed, and heavily drilled in school)
You’re not limited by homophony: almost all characters have a unique representation with four or fewer keystrokes
Faster typing but it’s a skill that needs practice
For example, to type 很高兴见到你 with Wubi, you enter tve ym iw mqb gc wq.

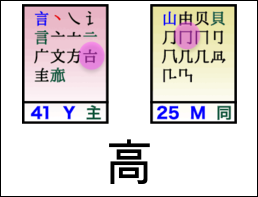
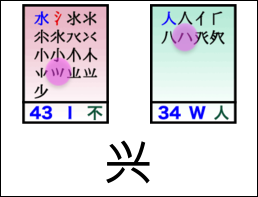
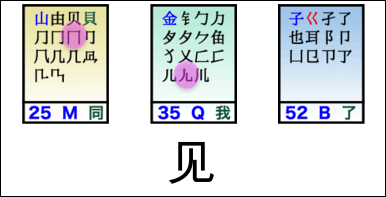
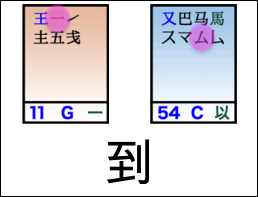
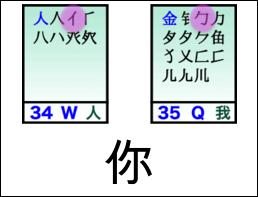
Notes:
For more details, especially for the caveat about 见, see Joe Wicentowski’s exposition, specifically the Isolation Rule.
This sequence of Wubi strokes was derived from this Wubi86 layout, the wubi Python package, and some custom code.
Notes:
Video: Fluent in Mandarin again
Introduced mid-2008 with iOS 2.0 (recall copy-paste was added iOS 3.0, mid-2009).
Rather than develop phonetic pinyin-to-characters libraries for the many languages of the Sinosphere—Cantonese, Shanghaiese, Fujianese, Hakka, etc.—handwriting recognition allows all these speakers to readily enter text.
Most recently: speech-to-text.
Simplified vs traditional?—hold on to that question, it’s wierder than you think

Notes:
Image: Cry for the Noble Saichō by Emperor Saga on the death of Saichō, circa 822 CE. Saichō and a fellow Buddhist monk Kūkai are said to have introduced tea to Japan from China. Source
Japanese as a spoken language is totally unrelated to Chinese!
But Japan was a cultural vassal of China for much of the last 1500 years, like all nations that orbited the Middle Kingdom (“middle” as in, middle of the world), so it adopted (and adapted!) both Chinese characters and those characters’ Chinese pronunciation.

麒麟 = “qí lín” vs “ki rin” — “🦒”
漢字 = “hàn zì” vs “kan ji” — “Chinese character”
天使 = “tiān shǐ” vs “ten shi” — “👼”
Notes:
Image: MIKI Yoshihito’s photo of a Kirin beer advertisement
As characters were imported from China over the Tang and Song and later dynasties, some were used to write native Japanese words, but many represented totally new concepts lacking native equivalents (e.g., Buddhist terms), and Japanese scholars pronounced these the same as the Middle Chinese.
Over the last thousand years, Chinese loanwords have been thoroughly Japanified: the majority of Chinese characters have both a Chinese-derived pronunciation and a Japanese-native pronunciation.
A gentle analogy may be—English often has a more learned French/Latin-derived term for something and a down-to-earth Norse-derived equivalent: inquire/ask, commence/begin, purchase/buy (Wikipedia has a ton of these!).
Students begin learning to write Chinese characters in first grade, and by the time they finish high school, they are tested on mastery of 2,136 characters’ readings. These are an integral part of Japanese writing but not the whole story.

Notes:
Image: woodblock print by Komatsuken in 1765 (source) of Murasaki Shikibu, who finished The Tale of Genji circa 1012 CE. Though very popular, the earliest extant manuscript is from more than 200 years later. It is likely to have been written in both kanji and hiragana.
Over a thousand years ago, Japanese men and women developed their own syllabaries, like bopomofo, that encode the sounds of spoken Japanese with simplified Chinese characters.
Heian court ladies developed hiragana: ひらがな (“hiragana” in hiragana; in katakana: ヒラガナ). More rounded and smooth, even when written with a brush.
Buddhist monks developed katakana: カタカナ (“katakana” in katakana; in hiragana: かたかな): sharp and angular.
Each has 46 symbols (encoding the 5×10 combinations of 5 vowels and 10 basic consonants, less some obsolete pairings), and are fully interchangeable.
| aiueo | aiueo | |
|---|---|---|
| ∅ | あいうえお | アイウエオ |
| k | かきくけこ | カキクケコ |
| s | さしすせそ | サシスセソ |
| t | たちつてと | タチツテト |
| n | なにぬねの | ナニヌネノ |
| h | はひふへほ | ハヒフヘホ |
| m | まみむめも | マミムメモ |
| y | や・ゆ・よ | ヤ・ユ・ヨ |
| r | らりるれろ | ラリルレロ |
| w | わ・・・を | ワ・・・ヲ |
| n | ん | ン |
Notes:
Each of these has very specific usage in modern Japanese orthography.
・・・
ブルームバーグ (“Burūmubāgu” for “Bloomberg”),
Notes:
Because Japanese has five vowels per consonants, and there are ten-ish consonants, a rather elegant solution is
If you hold down the consonant long enough, you see the four directional vowels to choose from via a swipe, with the fifth being “no swipe”.
Typing fast, you don’t need to wait for the vowel menu to unfold, you just “flick”.
Same efficiency hit as pinyin/bopomofo: usually the auto-suggestion has the Chinese characters you want but sometimes you have to stop and help it break homophony.
Notes:
Video: self, iPhone kana keyboard demo

Notes:
Image: via Ben Kuhn quoting Creative Selection by Ken Kocienda on this early design for the iPhone keyboard: “tap to get the top letter, swipe left/right to get the bottom letters”.

Notes:
Image: Makoto Shinkai, 君の名は。 (Your Name.) light novel.
Japanese, like Chinese, doesn’t use spaces to separate words. This makes segmentation a challenging machine-learning-intensive pre-processing step to natural language processing (NLP)
When you double-click Japanese text on desktop or long-press on mobile, the app usually does an ok job selecting what you think of as a “word”: Safari, Chrome, Word, etc., have built-in dictionaries to decide word boundaries.
Some (Firefox, Notepad) just select runs of adjacent hiragana/katakana/Chinese characters.
Others though (VS Code) just select the whole line 😢.
Notes:
For those interested in parsing Chinese text: start with chinese for Python, which combines segmentation and dictionary lookups. In my experience, the segmentation has been useful for Cantonese as well.
For Japanese, check out fugashi or SudachiPy, both for Python, though Sudachi’s main implementation is in Java.
(Japanese is harder to integrate segmentation with a dictionary: I have a rough project, Curtiz, that helps find dictionary entries.)
For parsing Korean, try KoNLPy and let me know.

Notes:
Image: opening page of 訓民正音 (훈민정음, “hun min jeong eum” in Korean, “kun min sei on” in Japanese, “Instructions to the nation for correct pronunciation”) by Sejong the Great, 1446. Source
Korean is linguistically another totally different language from Japanese and from Chinese, but due to millenia of cultural diffusion with China and unfortunately decades of occupation and colonization by Japan, a lot of vocabulary has transferred to it from both of these.
Like Japanese, Korean’s upper register is filled with words imported from Chinese during ancient times.
Examples
Notes:
Today, Chinese characters are not necessary to read or write Korean. High schoolers only learn Chinese characters in elective courses, and newspapers of record might have ~5% Chinese characters.

Notes:
Image: 9.5 meter tall statue of Sejong the Great installed in 2009 in Seoul. Republic of Korea
However, unlike in Japanese, the Koreans have hangul, a phonetic writing system. This is a Big Deal.
King Sejong the Great is said to have personally perfected hangul in 1443 and encouraged its spread despite the learned elite’s dislike. (He is also a perennial star and side character in Korean dramas.)
Hangul Day is a national holiday in both Koreas.
It’s a matter of national pride that this writing system is “perfect”: it’s logical, compact, easy to learn, and maps to the sounds of Korean very well.
ㄱ ㄴ ㄷ ㄹ ㅁ ㅂ ㅅ ㅇ ㅈ ㅊ ㅋ ㅌ ㅍ ㅎ
ㅏ ㅑ ㅓ ㅕ ㅗ ㅛ ㅜ ㅠ ㅡ ㅣ
Notes:
Hangul is made up of twenty-four symbols (called jamo): fourteen consonants (ㄱㄴㄷㄹㅁ…) and ten vowels (ㅏㅑㅓㅕㅗ…), plus several pairs of two-consonant and two-vowel combinations.
These symbols’ shapes are said to mimic the shape of the mouth when producing them.
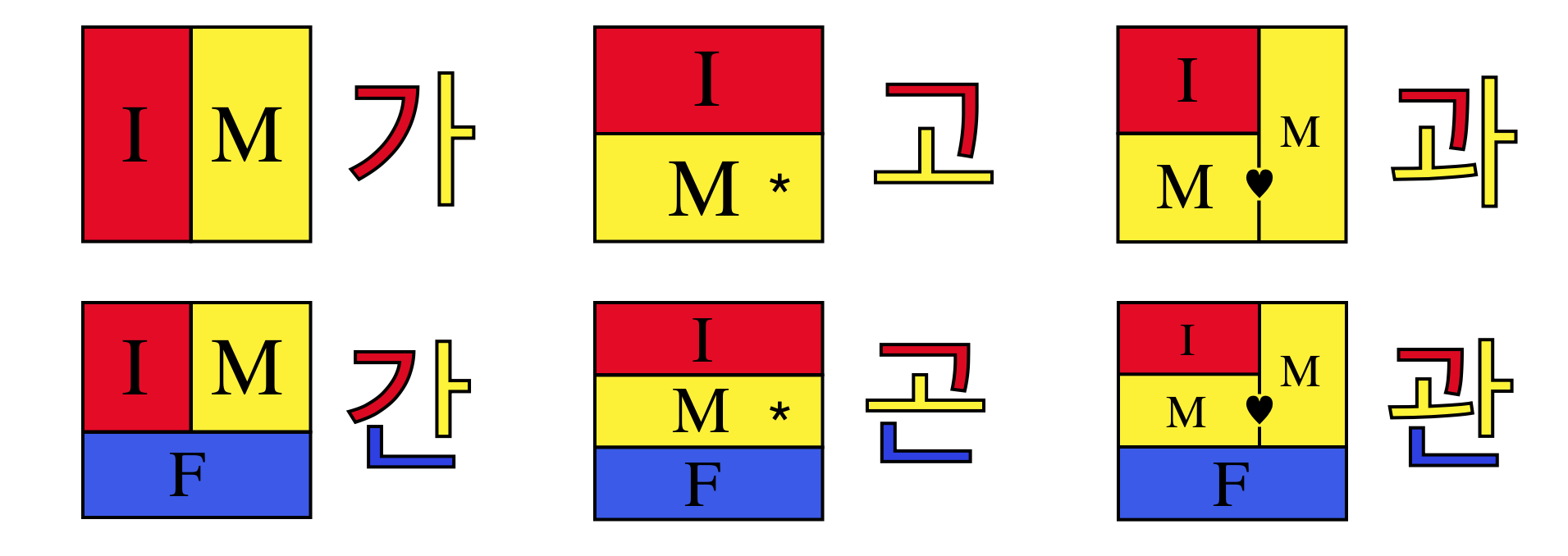
Notes:
Image: excerpt from a much more detailed chart of Hangul letter order from Wikipedia.
But the cool thing is, you don’t write these out linearly like bopomofo or hiragana or Latin—rather, these jamo combine into syllables in two dimensions.
This can happen because Korean morphemes (the smallest unit of meaning) are invariably made up of
These snap together like Legos, following straightforward rules depending on the length of the morpheme.
Hangul did not replace Chinese characters (hanja), then or now. Hangul only became official due to nationalism in the late 1800s.
Korean tends to be written with spaces so front-end NLP is easier than Chinese or Japanese.
Let’s talk about Unicode.
Notes:
A monumental achievement, today with Unicode 13 containing >140,000 code points.
But it’s driven by committees of experts, who are falliable.
Unicode 1.0 released in 1991 had 2,350 hangul syllables and jamo. This is far fewer than the full set of syllables that can be constructed. The rest were assumed to be typed and rendered by combining individuals, following the design of the Korean character set (KS X 1001) that Unicode followed.
Unicode 1.1 in 1993 added 4,300 more syllables, following KS X 1002 and another partial set, again far fewer than needed by modern Korean.
Unicode 1.0 was never an official or national standard, and 1.x were tentative. Both are obsolete.
Unicode 2.0 in in 1996 finally threw out all ~6,500 hangul characters and created the Hangul Syllables block in a totally different part of the plane containing all ~11,000 hangul and jamo used today. The obsolete hangul code points are now used for rare Chinese characters…
We give each full hangul syllable its own code point because, in UTF-8, 훯 (“hwolh”) is three bytes, and each of its combining components, ᄒ (“h”) and ᅯ (“wo”) and ᆶ (“lh”), is also three bytes.
In fact, try copy-pasting these three simpler hangul and then removing the spaces between them: ᄒ / ᅯ / ᆶ. Your operating system will seamlessly combine them into the larger Unicode code point (party trick via Gernot Katzer).

Notes:
Image: regional differences in a single character, 返 (かえ.る), per Wikipedia

Notes:
Image: from Lunde, CJKV Information Processing, table 3-99: regional differences for several characters
Unicode 2.0 also added ~21,000 Chinese characters; 3.0 in 1999 added ~6,500; 3.1 in 2001 added another ~43,000 (Table 3-82 in CJKV Information Processing).
From the beginning, their goal was to “unify all ideographs from the many CJKV national character set standards into a single set of ideographs” (Lunde, p. 155) and this came to have the problematic name, “Han unification”.
“Unification” sought to tame the bewildering amount of variation of characters across East and Southeast Asia such that characters that had the same
but varied by typeface (font) were assigned to a single Unicode point.
But this turned out to be a hard problem, from many linguistic and historical perspectives. Lunde: “Unfortunately, early standards were inconsistent in their encoding models for ideographs, and some still are” (p. 159).
At various points Unicode incorrectly failed to unify characters and was incorrectly too eager to unify.
All four of these are their own Unicode code points, and there’s a unified code point, 辶.
Notes:
Via @ken_lunde
Unification has been erratic even for characters that the PRC simplified in the 1950s and 1960s.
Today, things mostly just work. From users’ perspectives—your Google, Apple, Microsoft, etc., devices know what language you’re typing in and know what codepoints to use. As a developer, there are always surprises, and of course more work to do.
If only to make sure you don't end up like this:
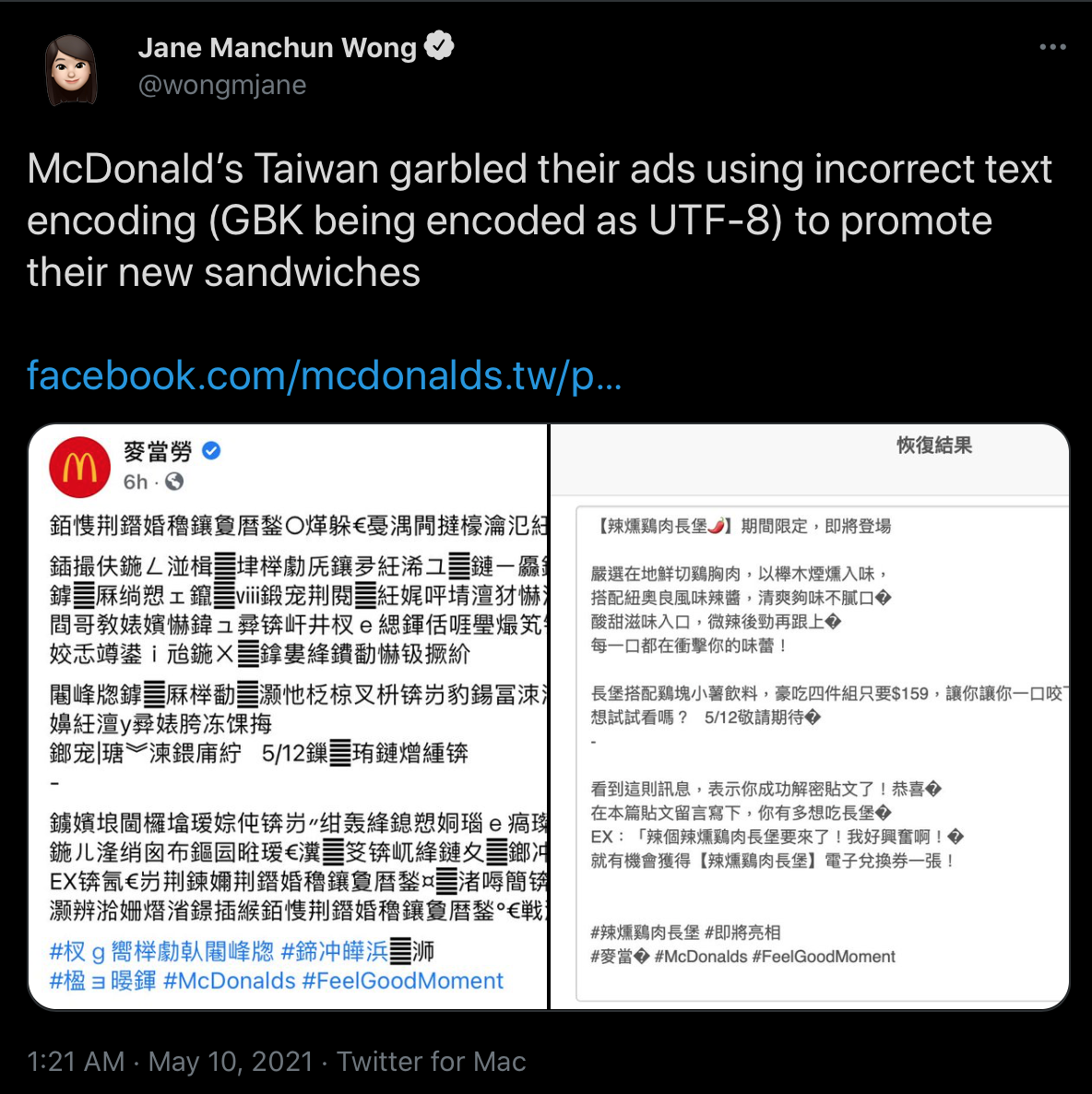
Notes:
Image: screenshot of @wongmjane: “McDonald’s Taiwan garbled their ads using incorrect text encoding (GBK being encoded as UTF-8) to promote their new sandwiches”.
Big Tech isn’t immune either: here’s Twitter messing up Han unification in Tweet Composer, also via @wongmjane. It’s such a problem that Kenji Iguchi created a website called Your Code Displays Japanese Wrong that Japanese readers can send to developers when, figuratively, their “ҭєxҭ lѳѳκs κιnd ѳf lικє ҭЋιs”.
We haven’t talked about ⥌vertical scripts⥍, fonts 🆃, emoji (^‿^), or waffles 🥞.
Notes:
This document lives as a Markdown file on GitHub: README.md
It was converted to a normal HTML page with Pandoc. You can see the exact Pandoc command in the build script. CSS derived from Perfect Motherfucking Website
This Markdown works perfectly with mark.show by @motyar! Here’s a direct link to view this document as a slideshow on mark.show
Text and my own photos/videos are relased under CC BY 4.0. (While I ordinarily release my creative content into the public domain (via Unlicense or CC0), I have chosen to release this under a Creative Commons Attribution license. My friends with less privilege than me and who can’t yet release your work completely unencumbered—I see you.)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}